



现代C/C++编译器有多智能?能做出什么厉害的优化?
编辑:佚名 日期:2024-05-13 09:11 / 人气:
请熟悉编译器的同学结合操作系统和硬件谈一谈现代c/c++编译器到底有多智能吧。哪些书本上的优化方法其实早就过时了?
以及程序员做什么会让编译器能更好的自动优化代码?
举个栗子:
1,循环展开,大部分编译器设置flag后会自动展开;
2,顺序SIMD优化,大部分编译器设置flag后也会自动优化成SIMD指令;
3,减少中间变量,大部分编译器会自动优化掉中间变量;
etc.
查看代码对应的汇编:
Compiler Explorer
话题太大,码字花时间…
先放传送门好了。
请看Google的C++编译器组老大Chandler Carruth的演讲。这个演讲是从编译器研发工程师的角度出发,以Clang/LLVM编译C++为例,向一般C++程序员介绍理解编译器优化的思维模型。它讲解了C++编译器会做的一些常见优化,而不会深入到LLVM具体是如何实现这些优化的,所以即使不懂编译原理的C++程序员看这个演讲也不会有压力。
Understanding Compiler Optimization - Chandler Carruth - Opening Keynote Meeting C++ 2015
录像:https://www.youtube.com/watch?v=FnGCDLhaxKU(打不开请自备工具…)
Agner Fog写的优化手册也永远是值得参考的文档。其中的C++优化手册:
Optimizing software in C++ - An optimization guide for Windows, Linux and Mac platforms - Agner Fog要稍微深入一点的话,GCC和LLVM的文档其实都对各自的内部实现有不错的介绍。
GCC:
GNU Compiler Collection (GCC) InternalsLLVM:
LLVM’s Analysis and Transform Passes========================================
反模式(anti-patterns)
1. 为了“优化”而减少源码中局部变量的个数
这可能是最没用的手工“优化”了。特别是遇到在高级语言中“不用临时变量来交换两个变量”这种场景的时候。
看另一个问题有感:
有什么像a=a+b;b=a-b;a=a-b;这样的算法或者知识? - 编程2. 为了“优化”而把应该传值的参数改为传引用
(待续…)
举个微小的例子,一到一百求和
#include <stdio.h>
int sum(){
int ret=0;
int i;
for(i=1; i <=100; i++) ret+=i;
return ret;
}
int main(){
printf("%d\
", sum());
return 0;
}
不开优化编译,汇编代码还挺正常的,乖乖做loop
.LBB0_1: #=>This Inner Loop Header: Depth=1
cmpl $100, -8(%rbp)
jg .LBB0_4
# BB#2: # in Loop: Header=BB0_1 Depth=1
movl -8(%rbp), %eax
movl -4(%rbp), %ecx
addl %eax, %ecx
movl %ecx, -4(%rbp)
开优化再看看汇编,clang -O2 -S sum.c
output:
# BB#0:
movl $5050, %eax # imm=0x13BA
ret
...
.Ltmp2:
.cfi_def_cfa_offset 16
movl $.L.str, %edi
movl $5050, %esi # imm=0x13BA
xorl %eax, %eax
callq printf
xorl %eax, %eax
popq %rdx
ret
卧槽,5050是个什么鬼!编译器大哥你能不能严肃点,直接把结果算出来是怎么回事。
编译器:算一加到一百都要写循环,妈的智障。
介于编译器会高斯求和法,估计大约是高斯十岁的水平【大误
利用C++11的range-based for loop语法可以实现类似python里的range生成器,也就是实现一个range对象,使得
for(auto i : range(start, stop, step))
功能上相当于
for(auto i = start, i < stop; i += step)
一个简单的实现如下:
#include<iostream>
using std::cout;
class range_iterator {
public:
range_iterator(int value, int step): value(value), step(step) {}
range_iterator& operator++() { value += step; return *this; }
bool operator!=(const range_iterator& other) { return value < other.value; }
int& operator*() { return value; }
private:
int value, step;
};
class range {
public:
range(int start, int stop, int step): start(start), stop(stop), step(step) {}
range_iterator begin() { return range_iterator(start, step); }
range_iterator end() { return range_iterator(stop, step); }
private:
int start, stop, step;
};
int main() {
int op, ed, step;
std::cin >> op >> ed >> step;
for (int i : range(op, ed, step)) {
std::cout << i << std::endl;
}
system("pause");
}
用VS2015在release下编译,看下反汇编:
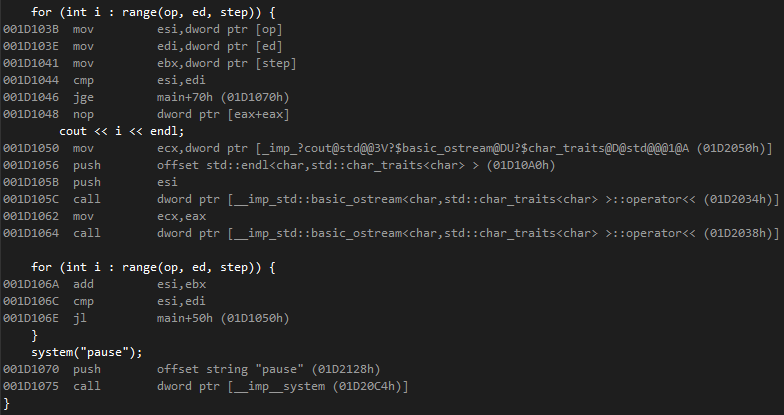
可以发现根本没有实例化过任何range和range_iterator对象,for循环里的内容已经被优化成了
for(int i=op; i < ed; i +=step)
我所知道的现在两个compiler大的方向是LTO跟autoFDO
LLVM Link Time Optimization: Design and Implementationlink time optimization 简单来说就是在link stage的时候再做一遍优化。现在所有的优化都是在生成.o 文件的时候做的,在链接的时候其实可以做更多的优化。 llvm给的例子如下
--- a.h ---
extern int foo1(void);
extern void foo2(void);
extern void foo4(void);
--- a.c ---
#include "a.h"
static signed int i=0;
void foo2(void){
i=-1;
}
static int foo3(){
foo4();
return 10;
}
int foo1(void){
int data=0;
if (i < 0)
data=foo3();
data=data + 42;
return data;
}
--- main.c ---
#include <stdio.h>
#include "a.h"
void foo4(void){
printf("Hi\
");
}
int main(){
return foo1();
}
linker在看到所有文件之后发现
1. foo2() 永远不会被调用,可以把foo2删掉
2. i 永远是0哦,没有人会改i 了
2. 那么i 永远不会小于0, foo3 也不回被调用,if 和foo3 全部删!删!删!
3.最后foo4 也可以被删掉,因为没人调用
这里给的例子相对trivial,但是大家可以大致理解为什么LTO厉害了吧。有上帝视角哦。
LTO的坏处是:
编译实在是太慢了!太慢了!大的软件上面要用LTO简直让人抓狂
GitHub - google/autofdo: AutoFDOFDO 是feedback driven optimization。很多Java的人都吹说jvm可以一边跑一边自动优化,现在通过FDO,c++的compiler也可以啦!
FDO的坏处是:
设置特别麻烦,对小公司来说现在还是太昂贵了。大公司基本上得在自己的服务器上定时去搜集这些信息,然后在编译时间总结一下。这个系统这是得大把真金白银砸出来的
看到高票答主
@苏远的回答提到了整数求和累加的优化,
我来说明下编译器的实现原理吧。
以如下代码为例,省略了其他无关代码:
int sum = 0;
for (int i = 0; i < 100; i++)
{
sum += i;
}
return sum;// 任意一条使用sum的语句
首先我们先转换为SSA形式(
wikipedia.org 的页面)的IR,这才能体现出编译器做的优化。
EntryBB:
i_0=0
sum_0=0
condBB:
i_2=phi(i_0, i_1) # i_0来自于基本块EntryBB, i_1来自于基本块bodyBB
sum_2=phi(sum_0, sum_1)
br i_2 < 100, bodyBB, endBB # 当条件i_2 < 100为真时,跳转到bodyBB,否则跳转到endBB
bodyBB:
r1=sum_2 + i_2
sum_1=r1
i_1=i_2 + 1
goto condBB
endBB:
return sum_2为了得到
@苏远所示代码中的结果,编译器会执行归纳标量简化优化(
Induction variable)。但是在执行这项优化之前,编译器会执行一趟分析趟——标量演化(Scalar Evolution),该项优化是针对循环链(chain of recurrencce)来处理的
1.
GNU Compiler Collection (GCC) Internals2.
http://cri.ensmp.fr/~pop/gcc/mar04/slides.pdf3.
http://icps.u-strasbg.fr/~pop/DEA_03_Pop.pdf4.
http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15745-s13/public/lectures/L6-LLVM-Detail-1up.pdf5.
Re: Identifying Chain of Recurrence6.
https://github.com/gcc-mirror/gcc/blob/master/gcc/tree-scalar-evolution.c用于确定每个标量在每次循环迭代的时候,值是多少,循环的迭代次数等。
那么以上述代码为例,我们可以知道变量i_2的chrec(chain of recurrence的缩写)的形式为{i_1, +, 1},也就是说i_2的值的变化公式为i_2=i_1 + 1*x (x为循环的迭代次数),因为i_1为常量,带入得到为i_2={0, +, 1}=x。
sum_2={sum_0, +, i_2}={sum_0, +, i_1, +, 1}={0, +, 0, +, 1}=0 + 0*x + 1* x(x-1)/2!=x^2/2 + x/2。
知道上述scalar evolution的信息之后,编译器会执行归纳变量化简。
又因为我们知道了循环的迭代次数为100,因为循环判断条件是循环不变式(Loop Invariant),那么我们就可以知道循环退出时sum_2的值,带入上述公式,得到sum_2的最终值为100 * 99 / 2=4950。然后直接替换endBB基本块中return sum_2为
return 4950。
那么在执行替换之后,循环就变为无用了,会被LoopDeletion趟(
LoopDeletion.cpp Source File)进行删除,最后优化完的IR为:
endBB:
return 4950
缺点:
可能很多人看了上述代码之后,感觉编译器好牛逼啊。但是上述方法的应用是有很多限制条件的。
1. 循环终结条件必须是Loop invariant,这样才能确定循环迭代次数(trip count)。
2. 所处理的变量是整数,目前无法对浮点数进行处理,chrec只能处理整数。
3. 迭代次数有限制,这个视不同编译器不同。LLVM 2.6中初始最大迭代次数是100次。
内容搜索 Related Stories
推荐内容 Recommended
- 学习法律法规心得体会范文09-23
- 哪个平台提供原创带货视频?这些平台靠谱吗?09-23
- 山东电子竞技运动与管理专业大学排名及录取分数线(2025高考参考)09-23
- 【N4文法】~れる/られる/される(受身/受動態)09-23
- 生物药研发总监岗位职责08-14

