



关于鲁棒优化,各路大神知道多少,求给讲讲?
编辑:佚名 日期:2024-04-29 03:28 / 人气:
本人目前处于入门阶段,就所知和所读简单说一下。
时间轴来看,RO最早追溯到Soyster(1973)写的一篇Technical report. 之后20多年没有实质的发展,真正开始流行是在90年代末,Ben-Tal (著有robust optimization一书)等人研究了鲁棒线性优化问题,从2000年到现在,鲁棒优化持续活跃了15年,目前已经从静态鲁棒优化转向了多阶段动态鲁棒优化的研究。
我们通过一个投资组合的例子来理解RO研究动机。
现在我有1万元,可投资10种不同的风险资产(未来收益不确定uncertain)。但因为收益越大,风险越大,我需要在两者之间权衡,目标就是实现收益与损失概率的最优tradeoff。
如果未来收益概率分布已知,那该问题是传统的随机优化(SP: STOCHASTIC PROGRAM)。但现实中,历史数据提供的经验分布(EMPIRACAL DISTRIBUTION)并不能匹配对未来数据的预测,至多是partial information。概率分布不知道,那么如何考虑这个投资组合问题呢,此时就是要考虑使用RO啦。相比SP,RO是set-based 的,怎么理解?我们虽然不知道未来收益的具体分布,但是我们可以构造一个不确定集合(Uncertainty set),未来收益在这个集合中变化,robust的意思是由RO模型得到的解,任由收益如何变化,即使在最差情况下(worst-case),也是可行的(robust feasibility)。
从这个小例子可以大概知道RO是干啥的了。RO optimizes systems under uncertainty without knowing probability distribution or with partial distribution.
因为考虑worst-case,RO得到的结果具有一定的保守性(不够灵活),因为有时候其实最差的情况在现实中是不会发生的。不确定集合的结构对模型的解起直接影响,同时不确定集合的复杂程度,对于模型能否求解也起直接影响。RO研究的核心问题是理解不确定集合,在理解的基础上,构造合理的不确定集。
RO算是最优化领域较为年轻,但是非常活跃的研究话题。应用也非常广泛。工程,金融,供应链,机器学习等等。既然是优化方向,学好线性优化和凸优化是前提。
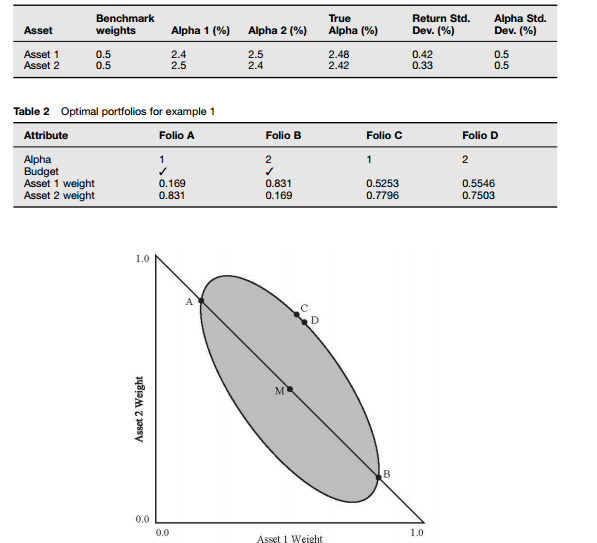
楼上的大神讲的差不多了,我来举一个简单的portfolio construction的例子, table1 和 table2 是两个资产的 expected return 和 standard deviation。 根据 efficient frontier 的理论构建一个mean-variance portfolio。求得最优的 asset weight。 但是从表还有图里可以看到如果expected return 选择的是 alpha1,那么得到的结果是 图中A点, 如果expected return 选择的是alpha2, 那么最后的结果是图中的B点。 A,B 两点得到的optimal portfolio 中资产的权重对调了,但是其实expected return并没有变多少,所以这种求optimal portfolio的方法是不稳健的, 因为一旦在测度中有误差,就会得到一个完全不同的结果,这个也一直是efficient frontier 最受人诟病的地方。而一个robust portfolio要求的是构建的portfolio在一定不确定性下是最优的portfolio。
(1)根据经验,大多数情况下estimation error 都在 expected return 中,risk 中的estimation error 比较小,所以最开始考虑expected return中的误差..
是estimate of expected return,
是真实值,
,
表示
落在上面区间里的概率.
如果 是full-rank 的 co-variance matrix, 那么mean-variance model 的optimization problem 就是。
通过 optimal condition 可以求出权重向量是
现在假设求得的权重向量是 固定, 真实的expected return 和 estimated expected return 得到的portfolio的 difference。
求得 就是在一定误差范围内和estimated expected return 会产生最大的difference 的 结果,也是得到的最低收益的结果:
这样最后的optimization problem 就是
这样的结果就是一个robust optimization 的结果。因为考虑了不确定性。
当然这是一个很简单的模型, 而且很保守,假定 portfolio manager 的estimated return 是在true expected return 对称分布的,可以再上面的最优化问题中加入一个新的constraint:
是对称可逆的矩阵。
如果设置,
total net adjustment to the expected returns is 0
如果设置 ,
Cholesky decomposition,
total net adjustment of standard deviation
如果设置 ,
zero net adjustment in the variance.
%%%-------------------------------------------------------------------------------------------------------------------
(2)上面的例子最大的问题就是只考虑了 first moment 没有考虑second moment。 如果考虑second moment, 肯定会有second order 的 constraint,如果直接处理, 会很麻烦, 所以这里可以引入semi-definite programming。
同时一个portfolio 经常需要rebalance 这样的操作,上面的例子没有考虑到transaction cost, 只考虑了single period 没有考虑因为rebalance 而产生的 multi-period问题。同时上面的formulation 并不是linear的,如果加入其他的一些限制比如说 tax 等等会很麻烦,所以除了上面提到的ellipsoid 的 formulation 也可以用 polyhedral 的 formulation 比如设定上下边界。
%%%---------------------------------------------------------------------------------------------------------------------
以上
提供一个数学实例
给定最优化问题
在区间不确定 (Intervall uncertain),就是约束条件里的系数可能会变。
且A,b变化如下
求鲁棒表达。
解:
约束条件1变为
,
因为是要在最坏情况下,所以这里把波动范围max,
最大值可改写为
,
令
约束条件1变为:
同理, 新的约束条件2:
约束3变为
最终表达
--------------------------------------原来的答案,针对不同的不确定性------------
在球型不确定( ellipsoid uncertain)前提下(即: ), 约束的系数表达式为:
并且约束波动和之前一样
求鲁棒优化表达式
解:根据条件 可知,
一般表达式可为:
则:
由此得到
同理可得 约束条件2 和3
最终转化为鲁棒优化
?实际问题中往往存在着许多不确定性,常见的处理不确定性问题的方法是随机规划、鲁棒优化等。一般我们都认为随机规划问题针对的是一个给定的概率分布,但实际中这个概率分布往往不能得到,通常只能通过历史数据去估计,但是当估计误差与真实分布相差较大时,随机规划的方案可能会带来极大的结果偏差。鲁棒优化不对不确定性变量做任何分布假设,而是通过构建不确定集,在其中寻找“最坏的情况最好”。
考虑一个由 个股票构成的投资组合问题,我们认为,投资股票$i$带来的未来回报为
,现在希望寻找一种投资组合策略,最大限度得提高总回报。这可以通过求解以下线性规划来实现:
其中 表示投资股票
的比例,第一个约束意味着我们希望所有的预算都被投资,而
表示我们希望避免卖空股票。但实际上这个问题刻画是不符合实际的,因为真正的投资回报是不确定的,我们称之为不确定收益率,表述为:
其中 为收益的均值,
为收益的上下波动,
为不确定性集,
属于0到1,表示实际需求的波动程度,用不确定性集刻画。
VaR可以定义为在给定置信区间下可能发生的最大损失金额。在特定场景下,它也可以被视为最严重的损失。例:假设以95%的置信度每月VaR为1亿美元,其含义为在正常情况下,在95%的几个月内,我们预计该基金的利润或损失不超过1亿美元。换句话说,在任何给定的月份损失1亿美元或以上的概率为5%。
VaR的不足在于:
1)它没有描述可能最严重的损失。
2)VaR没有描述左尾的损失。它指示了值发生的概率,但未能描述左尾损失的分布。
3)VaR估计既受模型风险也受实施风险的影响。模型风险源于错误的假设,而实施风险是实施过程中出错的风险。
条件风险价值(CVaR),也称为 expected shortfall (ES),是由概率定义的损失期望值。换句话说,是预期损失投资回报率低于预先指定的最坏情况的回报率。例:基金5%的VaR是-25%,其含义为,在5%的时间里,该基金的回报率低于-25%。
简单来说 0.95 VaR衡量的是95% 里面的损失,而0.95CVaR衡量了96%-100%里面的损失, 因此,CVaR的损失大于VaR。
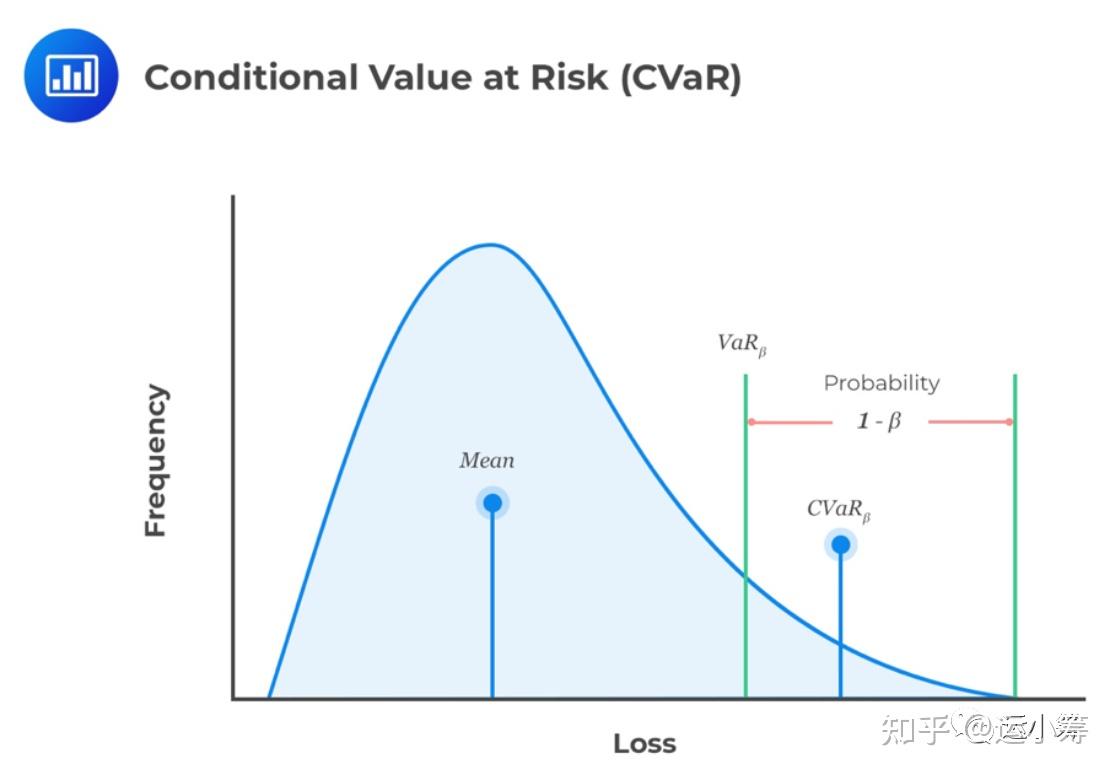
CVaR被认为是比VaR更好的风险衡量标准,因为与VaR不同,CVaR估计了不利事件的损失程度。我们构造CVaR不确定性集如下:
注意其中 是通过不同场景的安全平均求解z的值;
表示每个场景的出现概率大于等于0;
表示所有场景的概率和等于1;
表示每个出现概率小于等于一个上界。
是不确定性集大小的参数,可以简单地把
做为所有观察到的实现的集合[1]。如果我们想要找到最大的
,就是需要解决下面这个线性规划问题:
并令 。
原问题无法用solver直接求解因此需要进行reformulation。
step1: 将原问题写成epigraph form
step2: 对于step1中的约束(1),求证 ,即求解以下问题:
将 代入
step3: 对step2中的问题求对偶 :
step4: 原问题的reformulation为:
至此原问题就转化为了一个可直接用solver求解的线性规划问题。
rome是Joel Goh和Melvyn Sim开发的Matlab库,以促进鲁棒优化在线性规划建模的决策问题上的应用,常用于鲁棒模型的验证。该库在[2]中首次引入,可以用于以代数形式描述线性规划模型的细节,可在网站: http://www.robustopt.com 上下载并查阅相关文档。
接下来实现一个股票投资问题的CVaR不确定性集构造,并利用rome分别求解原模型和reformulation后的模型
VaRProb = 0.05;
n = 10; %number of stocks, 10
k = 120; %number of months, 120
%Generate parameters randomly
temp=rand(n,1);
returns=zeros(n,k);
for i=1:n
returns(i,:)=[rand(1,k)-repelem(0.5,k)+temp(i,1)];
end
Zs = returns-mu*ones(1,k); %
rhat = max(abs(Zs),[],2); % a column vector containing the maximum derivation of each row
Zs = diag(1./rhat)*Zs; % each row of Zs divide its maximum
P = diag(rhat);
% Calibrating the CVaR uncertainty set
h = rome_begin;
newvar gamma_CvaR;
newvar Theta(m,m);
for j=1:k %for Zs_j, use the jth column of Theta to do the combination
rome_constraint(Zs(:,j) == Zs*Theta(:,j));
rome_constraint(sum(Theta(:,j))==1);
end
rome_constraint(Theta <= gamma_CvaR/k);
rome_constraint(Theta>=0);
rome_minimize(gamma_CvaR);
h.solve;
obj_gamma_CvaR = h.objective;
Theta_Value = h.eval(Theta);
Theta_colum_max = sort(max(Theta_Value, [], 1)); % a row vector containing the maximum value of each column
Theta_CVaR =Theta_colum_max(k+1-ceil((1-VaRProb)*end));
alpha = 1/(Theta_CVaR*k);
rome_end;
% CvaR
disp('Solving the Origin model');
h = rome_begin;
newvar x(n) nonneg;
newvar y(1) ;
newvar z(n) uncertain;
newvar Theta(m) uncertain;
rome_constraint(z==returns*Theta);
rome_constraint(Theta>=0);
rome_constraint(sum(Theta)==1);
rome_constraint(Theta<=1/(k*alpha));
rome_maximize((mu+P*z)'*x);
rome_constraint(x<=1);
rome_constraint(sum(x)==1);
h.solve;
obj_CVaR = h.objective;
xx_CVaR = h.eval(x); %get optimal portfolio
rome_end;
string=['worstObjCvaR=',num2str(obj_CVaR)];
%print answer
disp(string);
%reformulation式
disp('Solving the Reformulation');
h = rome_begin;
newvar x(n) nonneg;
newvar lambda;
newvar y;
newvar beta(m) nonneg;
rome_maximize(y);
rome_constraint(-mu'*x+lambda+1/(k*alpha)*sum(beta)+y<=0);
for i=1:k
rome_constraint(lambda+beta(i)>=-((P*returns(:,i))'*x));
end
rome_constraint(x<=1);
rome_constraint(sum(x)==1);
h.solve;
obj_ref_CVaR = h.objective;
xx_ref_CVaR = h.eval(x);
rome_end;
string2=['worstObjCvaR2=',num2str(obj_ref_CVaR)];
%print answer
disp(string2);求解结果示例:

注意:由于案例数据随机生成,每次求解的目标值数值可能不一样,但是每次原模型和reformulation之后的模型结果应当一致。
[1]J. Goh and M. Sim. Robust optimization made easy with rome. Operations Research, 59(4):973–985, 2011.
[2]Delage 2019 LectureNotes_v8 Robust Optimization.
[3]https://analystprep.com/cfa-level-1-exam/portfolio-management/measuring-modifying-risks/
第85篇:非线性优化 | 非线性问题线性化以及求解的详细案例及Python+Gurobi求解
第84篇:ORers' Bling Chat | 【高光聊天记录集锦-02】:运小筹读者群里那些热烈的讨论
第83篇:Machine-Learning–Based Column Selection for Column Generation
第82篇:最新!205页运小筹优化理论学习笔记发布(2021年9月--2022年3月)!
第81篇:【鲁棒优化】| 补充证明:为什么最优解一定满足取值等于绝对值(论文笔记:The Price of Robustness)
第80篇:【鲁棒优化】| 论文笔记:The Price of Robustness - 列不确定性模型部分的推导和一些思考
第79篇:ORers' Bling Chat | 【高光聊天记录集锦-01】:运小筹读者群里那些热烈的讨论
第78篇:优化| 手把手教你学会杉数求解器(COPT)的安装、配置与测试
第77篇:【教学视频】优化 | 线性化(2):连续变量 * 0-1变量的线性化
第76篇:【教学视频】优化 | 线性化:两个0-1变量相乘的线性化
第75篇:强化学习实战 | DQN和Double DQN保姆级教程:以Cart-Pole为例
第74篇:强化学习| 概念梳理:强化学习、马尔科夫决策过程与动态规划
第73篇:强化学习实战 | Q-learning求解最短路(SPP)问题
第72篇:鲁棒优化 | 以Coding入门鲁棒优化:以一个例子引入(二)
第71篇:鲁棒优化|基于ROME编程入门鲁棒优化:以一个例子引入(一)
第70篇:优化|含分式的非线性规划求解: 基于Outer Approximation的Branch-and-cut 算法及其Java实现
第69篇:科研工具 | 手把手教你玩转文献管理神器:Endnote
第68篇:相约深圳 | 2022 INFORMS 服务科学国际会议·征稿通知
第67篇:鲁棒优化| 利用rome求解鲁棒优化简单案例:以CVaR不确定性集为例
第65篇:最新!145页运小筹优化理论学习笔记发布(2021年4月--9月)!
第64篇:优化 | 手把手教你用Python调用SCIP求解最优化模型
第63篇:优化 | 随机规划案例:The value of the stochastic solution
第62篇:工具 | draw.io: 科研流程示意图必备大杀器
第61篇:优化 | 开源求解器SCIP的安装与入门教程(Windows+Python)
第60篇:优化|Gurobi处理非线性目标函数和约束的详细案例
第58篇:测试算例下载:《运筹优化常用模型、算法及案例实战:代码手册》
第57篇:鲁棒优化|分布式鲁棒优化转化为SOCP案例及代码实现(Python+RSOME)
第56篇:鲁棒优化 | 分布式鲁棒优化简单案例及实战(RSOME+Gurobi)
第55篇:【尾款+发货】|【代码手册】 《运筹优化常用模型、算法及案例实战:Python+Java
第52篇:【视频讲解】CPLEX的OPL语言:可视化的优化模型求解解决方案
第51篇:算法 | 基于英雄联盟寻路背景的A星算法及python实现
第50篇:【转发】清华大学深圳国际研究生院2021年物流工程与管理项目优秀大学生夏令营报名通知
第49篇:优化 | 精确算法之分支定界介绍和实现(附Python代码)
第47篇:【重新发布】|《运筹优化常用模型、算法及案例实战:Python+Java实现》 【代码手册】 开始预购啦!!!
第46篇:智慧交通可视化:手把手教你用Python做出行数据可视化-osmnx 包入门教程
第45篇:优化 | Pick and delivery problem的介绍与建模实现(二)
第43篇:元启发式算法 | 遗传算法(GA)解决TSP问题(Python实现)
第42篇:优化|视频详解Python调用Gurobi的应用案例:TSP
第38篇:浅谈 | P问题、NP问题、NPC问题、NP-Hard问题
第35篇:优化|高级建模方法(Gurobi):线性化表达小技巧
第34篇:深度强化学习介绍 | Deep Q Network——理论与代码实现
第32篇:优化 | Pick and delivery problem的简介与建模实现(一)
第30篇:“Learn to Improve”(L2I):ICLR文章分享 | 运用RL解决VRP问题
第29篇:线性规划求解小程序 | 基于Python 的Cplex 求解器图形化界面
第27篇:Julia安装与配置Jupyter Notebook
第26篇:期刊征文| IEEE TRANSACTIONS应对COVID-19的特刊征文消息速递
第25篇:两阶段随机规划(Two-stage Stochastic Programming):一个详细的例子
第23篇:Python调用Gurobi:Assignment Problem简单案例
第20篇:运筹学与管理科学TOP期刊揭秘 —Service Science
第19篇:手把手教你用Python实现Dijkstra算法(伪代码+Python实现)
第18篇:运筹学与管理科学大揭秘—TOP期刊主编及研究方向一览
第17篇:优化 | 手把手教你用Python实现动态规划Labeling算法求解SPPRC问题
第16篇:代码 | 运小筹GitHub项目上线啦,快来标星收藏吧!!
第14篇:优化| 手把手教你用Python实现Dijkstra算法(附Python代码和可视化)
第13篇:优化|手把手教你用Python调用Gurobi求解最短路问题
第11篇:优化| 手把手教你用Python调用Gurobi求解VRPTW
第10篇:优化 | 两阶段启发式算法求解带时间窗车辆路径问题(附Java代码)
第7篇:优化 | TSP中两种不同消除子环路的方法及Callback实现(Python调用Gurobi求解)
第6篇:元启发式算法 | 禁忌搜索(Tabu Search)解决TSP问题(Python代码实现)
第5篇:论文代码复现 | 无人机与卡车联合配送(Python+Gurobi)
第4篇:优化|Shortest Path Problem及其对偶问题的一些探讨(附Python调用Gurobi实现)
第3篇:可视化|Python+OpenStreetMap的交通数据可视化(二):OpenStreetMap+Python画城市交通路网图
第1篇:Python+networkX+OpenStreetMap实现交通数据可视化(一):用OpenStreetMap下载地图数据
运小筹公众号致力于分享运筹优化(LP、MIP、NLP、随机规划、鲁棒优化)、凸优化、强化学习等研究领域的内容以及涉及到的算法的代码实现。编程语言和工具包括Java、Python、Matlab、CPLEX、Gurobi、SCIP 等。欢迎广大同行投稿!欢迎大家关注我们的公众号“运小筹”以及粉丝群!
可以私信编辑 MunSum3 拉入读者群
作者:杨影, 清华大学,深圳国际研究生院物流工程与管理
编辑: 张瑞三, 四川大学, 硕士在读, 邮箱:zrssum3@stu.scu.edu.cn、sum3rebirth@gmail.com
自从2013年的求解两阶段鲁棒优化模型的列和约束生成算法(CC&G)被提出之后,基本没有实质性的创新,都是围绕该算法在各个领域的深度应用,有些小的变形应用也都是基于模型应用,比如嵌套CCG等。所以这些年大热的CC&G研究在算法改进方面鲜有成就,电气专业同学在研究源荷不确定性的过程中基本都要学习该算法,明确求解流程、主子问题研究内容以及对偶、kkt条件等,现给大家推荐一个新鲜出炉的改进算法i-CCG。

一般两阶段鲁棒优化调度模型是 min-max-min 形式的非凸优化问题,难以直接求解。目前常用 Benders 分解或 C&CG 算法将该类型问题转化为包含 min 主问题和 max-min 子问题的两阶段优化。若模型第三层仅包含连续变量,则 max-min子问题可通过强对偶理论或 KKT(Karush-Kuhn-Tucker)条件等效为单层max问题,此时通过主问题和子问题的迭代计算即可求解出优化结果。相较于 Benders分解,C&CG 算法能在较少的迭代次数内达到收敛,其求解效率较高,主要原因为:
1)C&CG 算法在求解子问题时对场景进行严格辨识以缩减模型求解的搜索域;
2)C&CG 算法在求解主问题时保持了主问题的原始模型架构,而 Benders分解利用对偶割平面构建主问题,破坏了原始模型架构,增加了模型计算量。
因此 C&CG 算法已经成为求解两阶段鲁棒优化问题的主要方法。
该算法是在2023年刚发表的文章《An inexact column-and-constraint generation method to solve two-stage robust optimization problems》提出来的,有兴趣同学可以下载学习一下,因为是刚发布的算法,用该算法建模型、求解、对比分析和增加小的改动都会提高文章的创新性,解决发表文章难的问题。
目的:该算法是为了解决CCG算法应用于大规模求解或者较难的模型求解速度慢的难题,虽然通过牺牲求解精度来提升求解速度,但是通过迭代参数设置以及求解步骤能够保证最终的结果收敛于最优解。
算法步骤:传统CCG的求解步骤如下:

研究过的同学应该比较了解,传统两阶段鲁棒主要是主子问题的循环迭代,子问题需要通过强对偶或者KKT条件得到最恶劣运行工况,通过增加变量的形式带入主问题,通过迭代获得最优解。整个逻辑比较简单,容易理解,虽然程序语言实现过程中会遇到各种坑,但是基本思路还是挺容易理解的。
i-CCG算法步骤:

该算法初始阶段通过牺牲求解精度(设置emp的值)来达到快速求解的目的,在循环迭代过程中增加了不精确求解变量(相当于在传统CCG算法中增加了一个缓冲层),并对求解的状态进行识别,不同求解状态下会进入不同的循环阶段,直至收敛到阈值以下。
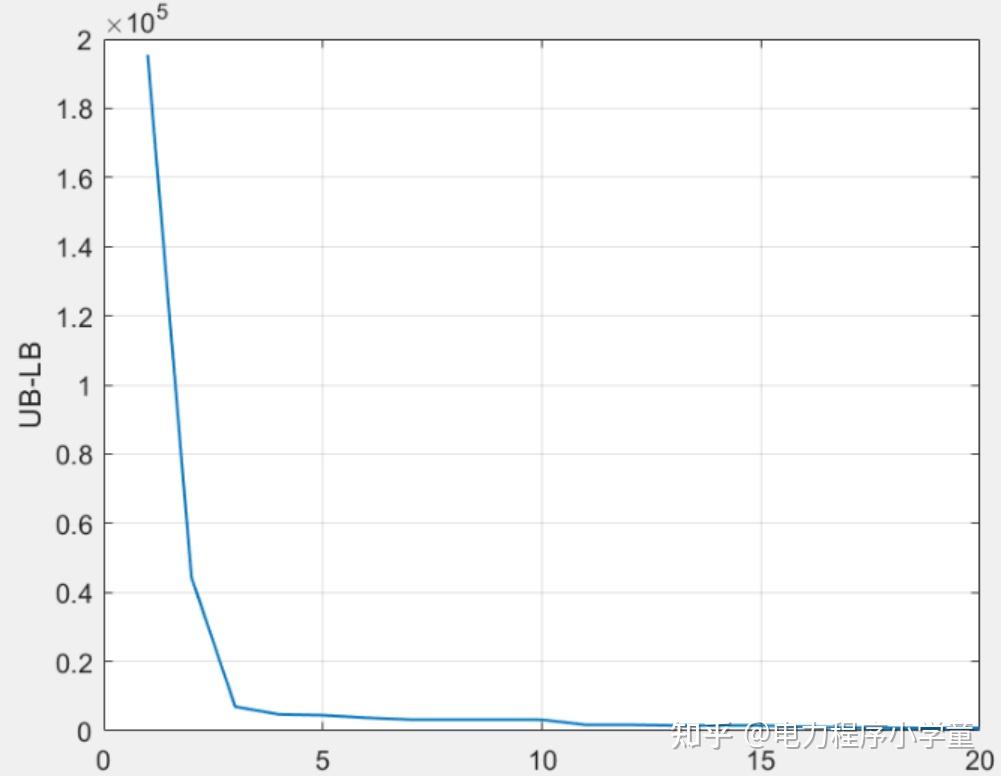
以《6节点电网两阶段鲁棒优化调度matlab》为例进行算法验证,常规算法下的迭代收敛曲线如下:
i-CCG算法的收敛曲线如下:
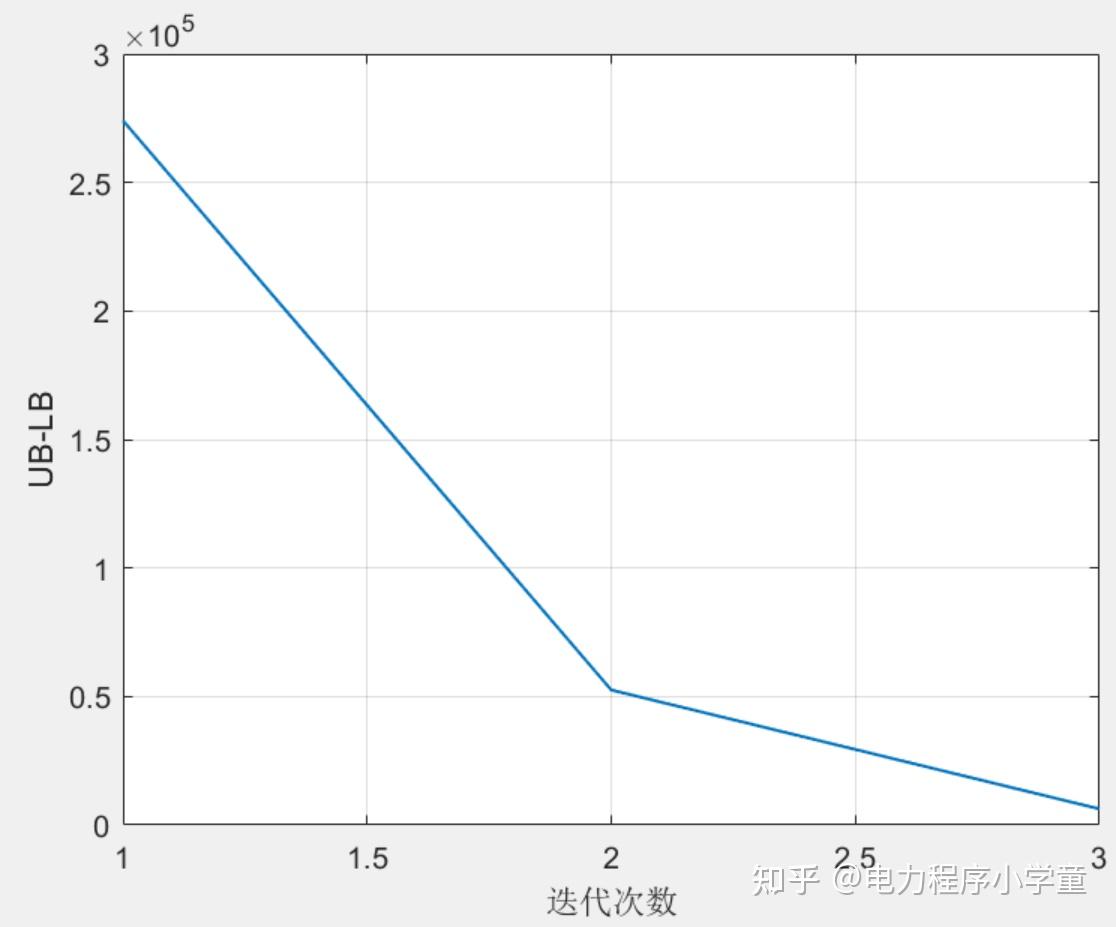
很显然,该改进算法的性能确实要好很多,通过实际程序求解时间都能明显感受到i-CCG算法求解速度快得多,因此,大家可以借用新算法开展深入研究和应用,祝大家SCI/EI/核心随便就能中!
内容搜索 Related Stories
推荐内容 Recommended
- 学习法律法规心得体会范文09-23
- 哪个平台提供原创带货视频?这些平台靠谱吗?09-23
- 山东电子竞技运动与管理专业大学排名及录取分数线(2025高考参考)09-23
- 【N4文法】~れる/られる/される(受身/受動態)09-23
- 生物药研发总监岗位职责08-14

